2026年4月10日 | 技术科普 + 原理讲解 + 代码示例 + 面试要点
一、开篇引入

AI漫画生成,无疑是2026年AIGC领域最炙手可热的赛道之一。从FLUX系列模型到Comic-Diffusion V2,从LlamaGen的端到端平台到DiffSensei的多角色控制框架,技术迭代之快令人目不暇接。很多学习者在接触AI漫画助手教学时,常常陷入“只会用工具、不懂底层原理”的困境——会用Midjourney画单张美图,却搞不定多格漫画的角色一致性;知道LoRA能微调,却说不清扩散模型到底是怎么“学会”画漫画的;面试被问到“如何保证主角在多页中长相不变”时,更是无从答起。
本文将从底层逻辑出发,带你理清AI漫画生成的技术脉络。从“为什么需要AI漫画生成”开始,深入讲解扩散模型与多智能体协作两大核心概念,梳理它们的逻辑关系,通过完整的代码示例展示从文案到多格漫画的实现过程,最后提炼高频面试题与标准答案。
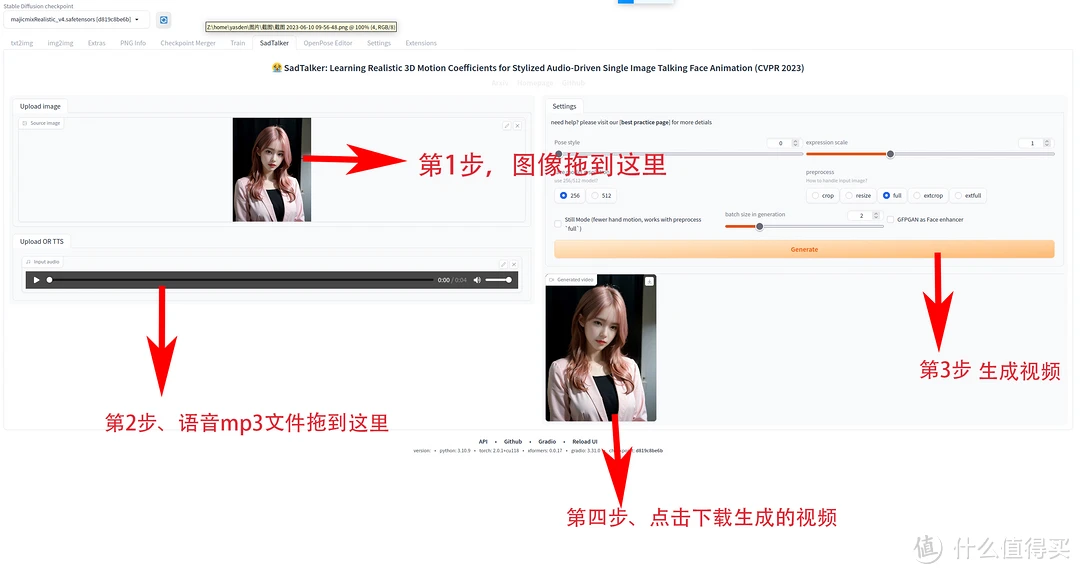
二、痛点切入:为什么需要AI漫画生成?
传统漫画创作的高门槛
先看一组数据:雇佣专业画师创作漫画的成本约为每页50至300美元,一本100页的图像小说需要5000到30000美元的投资-3。这还不包括创作周期——完成一部完整漫画往往需要数月甚至数年。
代码层面的痛点更直接。假设你试图用最原始的AI绘图方式来生成多格漫画:
❌ 传统方式:每格独立生成,毫无连贯性 import requests def generate_panel(prompt): 每次调用都是独立的推理 return image_generation_api(prompt) 生成四格漫画 panel_1 = generate_panel("一个戴眼镜的少年在房间里看书") panel_2 = generate_panel("同样的少年在学校操场上跑步") 问题:这个少年很可能“换脸”了 panel_3 = generate_panel("还是那个少年,和朋友说话") 问题:发型、衣服都变了 panel_4 = generate_panel("少年笑着挥手告别") 问题:角色身份彻底丢失
三大痛点
角色一致性差:普通AI绘图工具每次生图均为独立推理,无法记忆前一帧的角色特征,导致主角面部特征、发型、服饰在不同画面中突变,破坏叙事连贯性-14。
图文割裂:单张图片质量虽高,但与故事情节关联度低,难以形成完整的叙事链条。
多格布局失控:模型无法理解“第一格→第二格→第三格”的时间顺序和因果逻辑,分镜布局需要大量人工干预。
正是这些痛点的存在,催生了专门面向漫画生成的AI模型和工作流。
三、核心概念讲解:扩散模型(Diffusion Model)
定义
扩散模型(Diffusion Model) 是一种生成式人工智能模型,通过逐步向数据中添加噪声再学习反向去噪过程,从纯噪声中逐步还原出目标图像。
关键词拆解
正向过程(Forward Process) :像往一杯清水里滴墨水,逐步添加噪声,直到图像完全变成随机噪声。
反向过程(Reverse Process) :模型学习如何一步步“去噪”,从噪声中重建出清晰的图像。
调度器(Scheduler) :控制噪声添加和去除的速度与节奏。
生活化类比
想象一个雕塑家面对一块大理石。正向过程就像把一座完成的雕塑敲成碎块;而扩散模型学的是反向——如何从一堆碎石中,按照特定的“指导说明”(即文本描述),把雕塑重新“雕”出来。每一步去除的“石屑”对应着模型预测的噪声,最终呈现出你想要的角色和场景。
核心价值
扩散模型解决了传统生成对抗网络(GAN)在图像质量、多样性和训练稳定性方面的诸多问题,已成为文生图领域的事实标准-53。在漫画生成场景中,它能够理解漫画独特的视觉语言——从动态的画格构图到富有表现力的角色姿势-1。
四、关联概念讲解:多智能体协作系统
定义
多智能体系统(Multi-Agent System, MAS) 是一种将复杂任务分解给多个专门化的AI智能体协同完成的架构,每个智能体负责特定的子任务。
与扩散模型的关系
如果说扩散模型是“画师”,那么多智能体系统就是“导演 + 编剧 + 分镜师 + 排版师”的团队组合。扩散模型负责生成图像,而多智能体系统负责规划——将长文案拆解、设计分镜、调度生成、拼接成页。
对比说明
| 维度 | 扩散模型(Diffusion Model) | 多智能体系统(Multi-Agent System) |
|---|---|---|
| 角色定位 | 图像生成器(执行层) | 任务规划与调度层 |
| 解决什么问题 | “怎么画” | “画什么、按什么顺序画” |
| 类比 | 画师 | 导演 + 编剧 + 分镜师 |
| 输入 | 文本描述(Prompt) | 长文案/故事脚本 |
| 输出 | 单张图像 | 完整的多格漫画页面 |
一句话总结
扩散模型是“手”,多智能体系统是“脑”——大脑拆解任务、指挥双手,最终完成一幅完整的多格漫画。
五、概念关系与区别总结
理解了扩散模型和多智能体系统之后,两者的关系可以用下图概括:
┌─────────────────────────────────────────────────────────┐ │ 多智能体系统(管理层) │ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │ │ 编剧Agent │→│ 分镜Agent │→│ 画师Agent │→│ 拼接Agent │ │ │ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │ │ ↓ ↓ ↓ ↓ │ │ 文案拆分 分镜设计 图像生成 排版输出 │ └─────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────┐ │ 扩散模型(执行层) │ │ 文本编码器 → U-Net去噪 → VAE解码 → 图像输出 │ └─────────────────────────────────────────────────────────┘
记忆要点:多智能体系统负责“拆解任务、编排流程”,扩散模型负责“把每张图画出来”。二者是编排与执行、思想与落地的关系。
六、代码/流程示例演示
下面展示一个基于LangGraph的多智能体漫画生成系统的核心实现-28。
✅ 多智能体漫画生成系统 - 核心工作流 基于 LangGraph 实现的多 Agent 协作 from langgraph.graph import StateGraph, END from typing import TypedDict, List import json 定义状态结构 class ComicState(TypedDict): original_content: str 原始文案 story_parts: List[str] 拆分后的情节部分 scripts: List[dict] 各部分的剧本 images: List[str] 生成的图像列表 final_comic: str 最终漫画拼接结果 ========== Agent 1: 文案拆分智能体 ========== def split_content(state: ComicState) -> ComicState: """将长文案拆分成独立的自然情节部分""" content = state["original_content"] 调用LLM进行智能拆分 prompt = f"""请将以下文案拆分成几个自然的情节部分: 原文案:{content} 拆分规则: - 每个部分是一个完整的情节片段 - 有明确的时间、地点、人物、事件 - 按照自然时间顺序输出JSON格式:{{"parts": ["部分1", "部分2"]}} """ 示例:假设LLM返回了拆分结果 parts = ["小明在房间里看书,外面下着雨", "雨停后,小明去公园散步,看到一只小猫", "小明和小猫成为朋友,一起玩耍", "傍晚,小明带着新朋友回家"] state["story_parts"] = parts return state ========== Agent 2: 编剧智能体 ========== def script_writer(state: ComicState) -> ComicState: """为每个情节部分生成四格漫画剧本""" scripts = [] for part in state["story_parts"]: 调用LLM生成4格漫画剧本 输出格式:每格包含 scene, characters, plot, dialogue, narration script = { "title": "小明与小猫咪", "theme": "友谊", "panels": [ {"panel": 1, "scene": "小明房间", "characters": "小明", "plot": "小明在窗前读书", "dialogue": "这本书真有趣"}, {"panel": 2, "scene": "公园", "characters": "小明、小猫", "plot": "小明看到一只淋湿的小猫", "dialogue": "小家伙,你还好吗?"}, {"panel": 3, "scene": "公园长椅", "characters": "小明、小猫", "plot": "小明给小猫擦干毛", "dialogue": "以后我照顾你"}, {"panel": 4, "scene": "小明家", "characters": "小明、小猫", "plot": "小明抱着小猫回家", "dialogue": "我们有新成员了"} ] } scripts.append(script) state["scripts"] = scripts return state ========== Agent 3: 插画师智能体 ========== def illustrator(state: ComicState) -> ComicState: """基于剧本生成每格图像(使用扩散模型)""" images = [] for script in state["scripts"]: for panel in script["panels"]: 构建生成提示词 prompt = f""" {panel['scene']}场景,{panel['characters']}, {panel['plot']},日系动漫风格, 角色要前后保持一致,高质量插图 """ 调用扩散模型API生成图像 image = diffusion_model.generate(prompt, character_ref=["character_embedding"], width=768, height=768) 示例:使用LlamaGen Comic API from comic import LlamaGenClient client = LlamaGenClient(apiKey="YOUR_API_KEY") result = await client.comics.generate({ prompt: prompt, panels: 4, style: "manga", character_consistency: True }) images.append(f"panel_{panel['panel']}.png") state["images"] = images return state ========== Agent 4: 拼接智能体 ========== def image_stitcher(state: ComicState) -> ComicState: """将生成的图像按画格布局拼接成完整漫画""" from PIL import Image 假设每张图尺寸为 768x768 2x2 网格布局 final_width = 768 2 final_height = 768 2 final_image = Image.new('RGB', (final_width, final_height)) 拼接逻辑... state["final_comic"] = "final_comic.png" return state ========== 构建工作流图 ========== workflow = StateGraph(ComicState) workflow.add_node("split", split_content) workflow.add_node("script", script_writer) workflow.add_node("illustrate", illustrator) workflow.add_node("stitch", image_stitcher) workflow.set_entry_point("split") workflow.add_edge("split", "script") workflow.add_edge("script", "illustrate") workflow.add_edge("illustrate", "stitch") workflow.add_edge("stitch", END) 执行工作流 app = workflow.compile() initial_state = {"original_content": "小明在下雨天救了一只小猫..."} result = app.invoke(initial_state)
关键注释说明
文案拆分智能体:使用LLM将长文案拆成自然情节片段,每个片段对应一幅四格漫画。
编剧智能体:基于每个情节片段生成4格漫画剧本,包含场景、人物、情节、对话。
插画师智能体:调用扩散模型API生成每格图像,通过
character_consistency: True或LoRA确保角色一致性。拼接智能体:将生成的图像按漫画格式拼接成完整页面。
与传统方式的对比
| 传统单图生成 | 多智能体工作流 |
|---|---|
| 每格独立生成,角色特征混乱 | 剧本先行,角色一致性贯穿始终 |
| 图文割裂,叙事逻辑缺失 | 文案→剧本→图像→排版,全链路贯通 |
| 需手动拼接排版 | 自动按画格布局拼接输出 |
七、底层原理/技术支撑
1. 扩散模型的核心架构
以Comic-Diffusion V2为例,其基于Stable Diffusion Pipeline构建,包含以下核心组件-36:
文本编码器(Text Encoder) :使用CLIP将文本描述编码为潜在空间向量。
调度器(Scheduler) :采用PNDMScheduler,控制1000步的去噪过程(参数:beta_start=0.00085, beta_end=0.012)。
U-Net:核心去噪组件,通过交叉注意力机制融合文本条件。
变分自编码器(VAE) :将潜在空间表示解码为最终图像。
2. 角色一致性的关键技术
LoRA(Low-Rank Adaptation,低秩自适应) 是解决角色一致性的核心技术。它通过在底模基础上添加一小部分可训练参数(通常仅几十到一百多兆),专门学习特定角色的特征,而不需要全量微调整个模型-41。在2026年,你只需上传5-10张角色图像,就能在不到10分钟内训练一个自定义LoRA-44。
身份嵌入(Identity Embedding) 则是另一种方式——从1-3张参考图像中提取角色的数学“指纹”,在生成新图像时作为条件输入,确保角色特征不被稀释-44。
3. 技术路线图
输入: 文案 + 角色参考图 ↓ [LLM] 文案拆分 + 剧本生成 ↓ [LoRA训练] 或 [身份嵌入提取] ↓ [扩散模型] 逐格生成(带角色一致性约束) ↓ [VAE解码] 高清图像输出 ↓ 输出: 完整多格漫画
八、高频面试题与参考答案
面试题1:扩散模型和GAN相比,在漫画生成场景中有什么优势?
参考答案(踩分点:质量 + 多样性 + 可控性):
扩散模型在漫画生成场景中的核心优势有三点:第一,图像质量更高,FID指标显著优于传统GAN;第二,生成多样性更强,不会像GAN那样出现模式坍塌;第三,可控性更好,可以通过文本条件精确引导图像内容,尤其适合需要保持角色一致性的多格漫画生成场景。-53
面试题2:如何在多格漫画生成中保证主角外观的一致性?
参考答案(踩分点:LoRA + 身份嵌入 + 参考图像):
保证角色一致性主要依赖三种技术手段:一是LoRA微调,上传5-10张角色图像,在底模上训练轻量级适配参数,生成时调用该LoRA;二是身份嵌入,从1-3张参考图中提取角色的数学特征向量,作为扩散模型的条件输入;三是在API层面启用角色一致性功能,如LlamaGen的character_consistency参数。实际应用中,LoRA+身份嵌入组合使用效果最佳。-44
面试题3:简述DiffSensei框架的核心设计思想。
参考答案(踩分点:MLLM + 扩散模型 + 掩码交叉注意力):
DiffSensei是CVPR 2025提出的首个定制化漫画生成框架。其核心思想是将多模态大语言模型与扩散模型桥接——MLLM充当文本兼容的身份适配器,动态调整角色特征以匹配每格的文本描述;扩散模型则负责具体图像生成。关键技术是掩码交叉注意力,无需直接像素迁移即可实现精确的布局控制和角色表情、姿势的灵活调整。配套的MangaZero数据集包含43264页漫画、427147个带注释的画格。-48
面试题4:Comic-Diffusion V2的风格混合原理是什么?
参考答案(踩分点:风格令牌 + 多风格同时训练):
Comic-Diffusion V2基于Stable Diffusion架构,通过同时训练6种不同的艺术风格,允许用户通过混合任意数量的风格令牌来创建独特且一致的漫画风格。即便改变相同令牌列表的顺序也会影响最终结果,因此提供了极大的风格探索空间。相比传统单一风格模型,这种方式显著提升了风格定制灵活性和创作效率。-36
面试题5:AI漫画生成系统如何实现从长文案到多格漫画的自动化?
参考答案(踩分点:多智能体 + LLM + 扩散模型):
自动化流程基于多智能体协作架构:首先由文案拆分智能体将长文案拆成独立的情节部分;然后编剧智能体(LLM)为每个部分生成4格漫画剧本;接着插画师智能体调用扩散模型逐格生成图像,同时启用LoRA确保角色一致性;最后由拼接智能体将图像按画格布局排版成完整漫画页面。整个流程通过LangGraph等框架串联为端到端工作流。-28
九、结尾总结
核心知识点回顾
扩散模型是AI漫画生成的底层引擎,通过正向加噪+反向去噪的方式从文本生成图像。
多智能体系统负责任务编排——将长文案拆解为剧本、调度生成、拼接输出。
二者关系:扩散模型是“执行层”,多智能体是“管理层”,共同完成从文案到多格漫画的全流程。
角色一致性的核心技术是LoRA微调和身份嵌入,5-10张图即可在10分钟内完成训练。
2026年最新进展:DiffSensei实现了MLLM+扩散模型的深度融合,Comic-Diffusion V2支持6风格令牌混合。
重点与易错点提示
⚠️ 易错点1:混淆扩散模型和GAN的原理——扩散模型是渐进去噪,GAN是生成器与判别器对抗训练。
⚠️ 易错点2:认为多智能体系统可以替代扩散模型——实际上是分工协作,不是替代关系。
⚠️ 易错点3:忽视数据集质量对LoRA训练的影响——“质”远重于“量”,50张高质量图像优于500张杂乱图片-41。
下篇预告
下一篇将深入LoRA微调实战,带你从数据集准备开始,手把手训练一个专属的二次元角色LoRA,并集成到ComfyUI工作流中,实现工业化级别的漫画批量生成。
本文为AI漫画助手教学系列第一篇,后续将持续更新进阶内容,欢迎关注。